LUDVIG: Learning-free Uplifting of 2D Visual features to Gaussian Splatting scenes
Published in International Conference on Computer Vision (ICCV), 2025
Juliette Marrie, Romain Menegaux, Michael Arbel, Diane Larlus, Julien Mairal
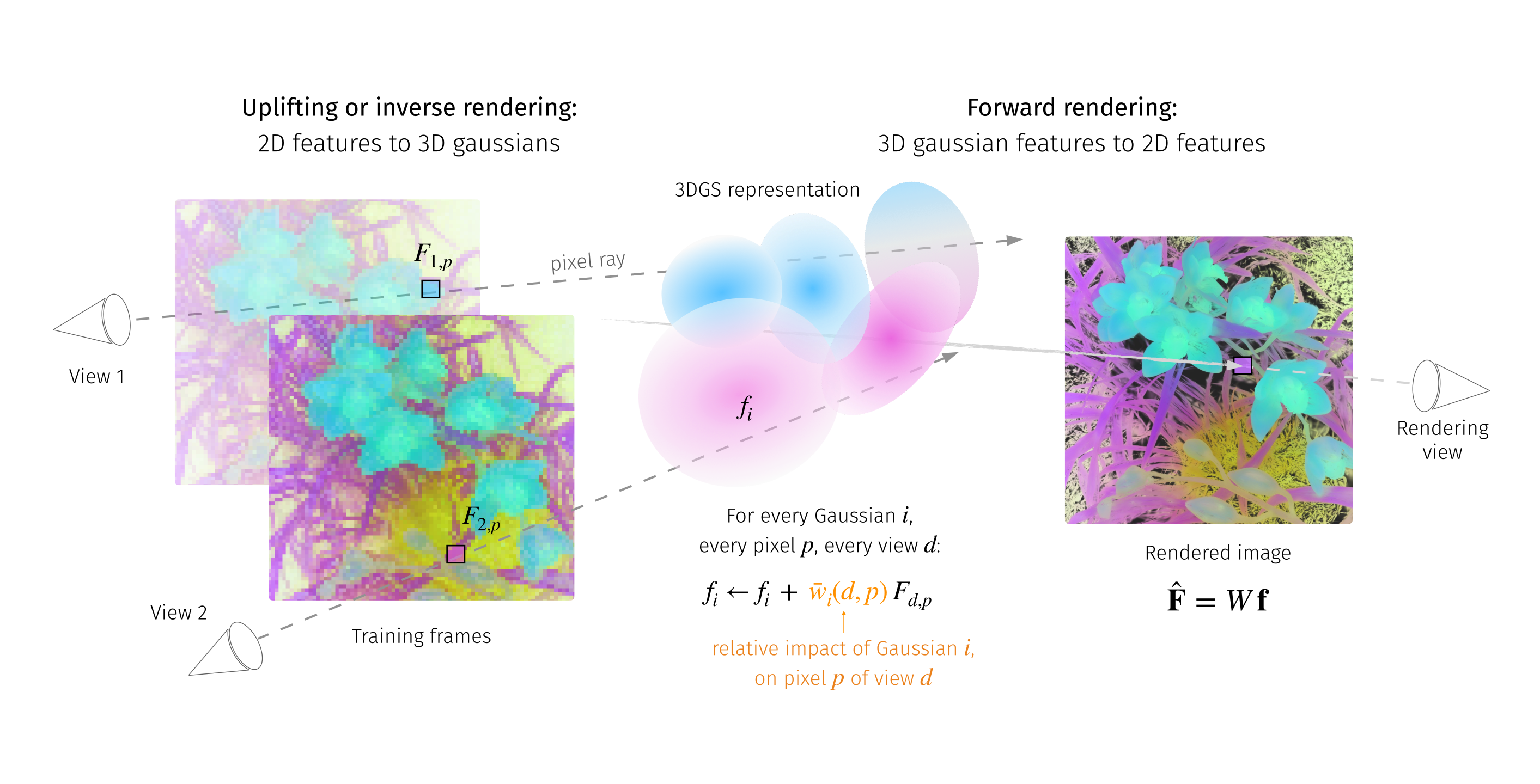
We address the problem of extending the capabilities of vision foundation models such as DINO, SAM, and CLIP, to 3D tasks. Specifically, we introduce a novel method to uplift 2D image features into 3D Gaussian Splatting scenes. Unlike traditional approaches that rely on minimizing a reconstruction loss, our method employs a simpler and more efficient feature aggregation technique, augmented by a graph diffusion mechanism. Graph diffusion enriches features from a given model, such as CLIP, by leveraging pairwise similarities that encode 3D geometry or similarities induced by another embedding like DINOv2. Our approach achieves performance comparable to the state of the art on multiple downstream tasks while delivering significant speed-ups. Notably, we obtain competitive segmentation results using generic DINOv2 features, despite DINOv2 not being trained on millions of annotated segmentation masks like SAM. When applied to CLIP features, our method demonstrates strong performance in open-vocabulary, language-based object detection tasks, highlighting the versatility of our approach.