
On Good Practices for Task-Specific Distillation of Large Pretrained Visual Models
Published in Transactions on Machine Learning Research (TMLR), 2024
Juliette Marrie, Michael Arbel, Julien Mairal, Diane Larlus
Large pretrained visual models exhibit remarkable generalization across diverse recognition tasks. Yet, real-world applications often demand compact models tailored to specific problems. Variants of knowledge distillation have been devised for such a purpose, enabling task-specific compact models (the students) to learn from a generic large pretrained one (the teacher). In this paper, we show that the excellent robustness and versatility of recent pretrained models challenge common practices established in the literature, calling for a new set of optimal guidelines for task-specific distillation. To address the lack of samples in downstream tasks, we also show that a variant of Mixup based on stable diffusion complements standard data augmentation. This strategy eliminates the need for engineered text prompts and improves distillation of generic models into streamlined specialized networks.
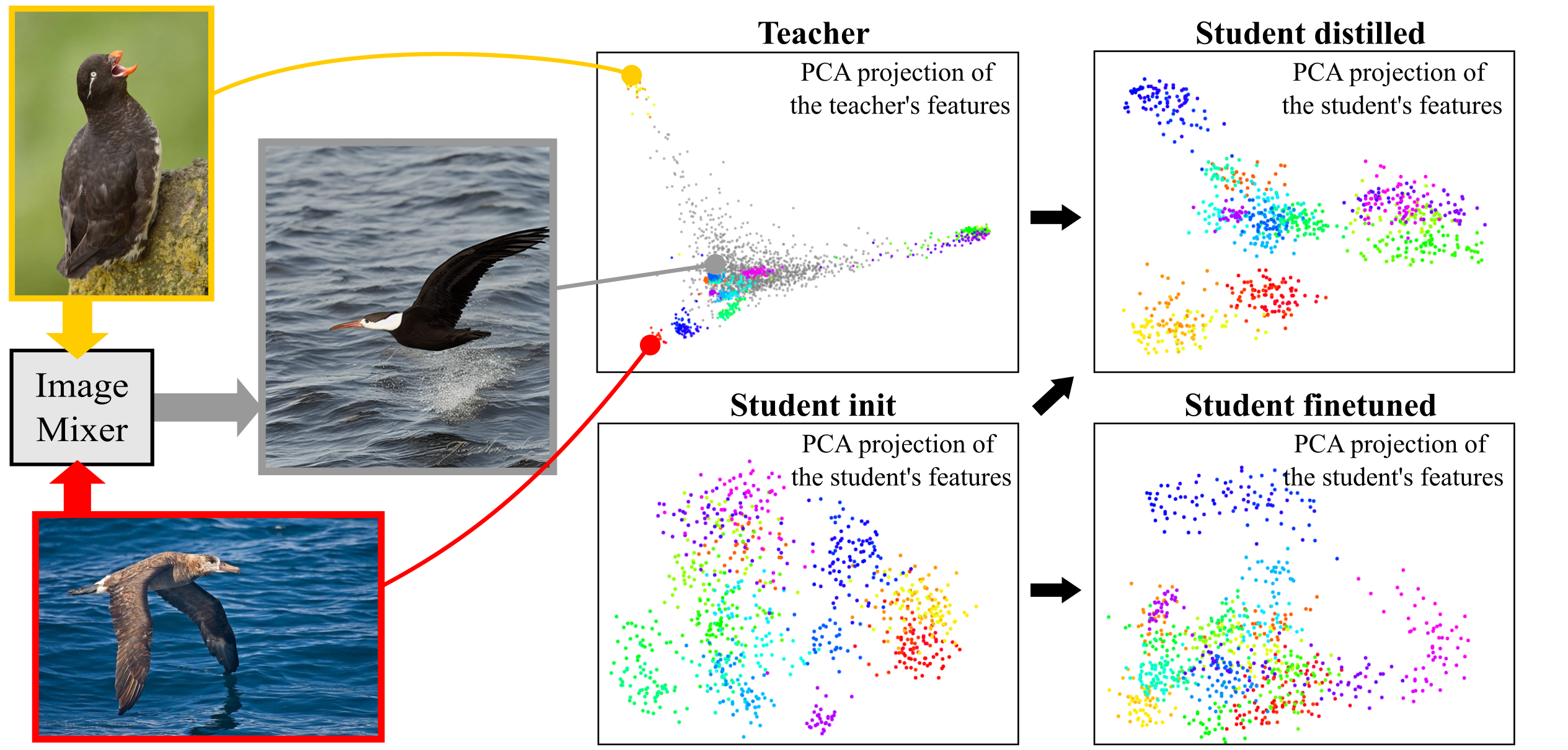
PCA of image features for 30 classes of the CUB Bird dataset. Distilling a large pretrained teacher (top, left) to train a small task-specific student model (top, right) results in a better clustering of the representations compared to simply finetuning the student on the task (bottom, right). Distillation can be improved by using a Mixup-inspired class-agnostic data augmentation based on Stable Diffusion (grey features in teacher plot).